Scraping TechCrunch articles to Excel report
In this blog post, we are going to scrape the latest TechCrunch articles and save them to an Excel report using BeautifulSoup, a Python library for scraping.
To run the example, download this Jupyter notebook.

Here are a few links you might be interested in:
- Intro to Machine Learning
- Intro to Programming
- Data Science for Business Leaders
- AI for Healthcare
- Autonomous Systems
- Learn SQL
Disclosure: Bear in mind that some of the links above are affiliate links and if you go through them to make a purchase I will earn a commission. Keep in mind that I link courses because of their quality and not because of the commission I receive from your purchases. The decision is yours, and whether or not you decide to buy something is completely up to you.
Setup
from platform import python_version
import bs4
import pandas as pd
import requests
import xlsxwriter
print("python version==%s" % python_version())
print("pandas==%s" % pd.__version__)
print("bs4==%s" % bs4.__version__)
print("requests==%s" % requests.__version__)
print("xlsxwriter==%s" % xlsxwriter.__version__)
python version==3.7.3
pandas==0.25.0
bs4==4.8.0
requests==2.21.0
xlsxwriter==1.2.1
1. Deciding what to scrape
Firstly, we need to decide what we would like to scrape from the website. In our example, these are the latest articles from TechCrunch (marked with a red square on the image below). For each article, we would like to scrape a title, short content and its URL.
Let’s inspect the HTML in a web browser (right-click on a webpage -> inspect) and look for a pattern in HTML elements that formats the latest articles (marked with a blue square on the image below).
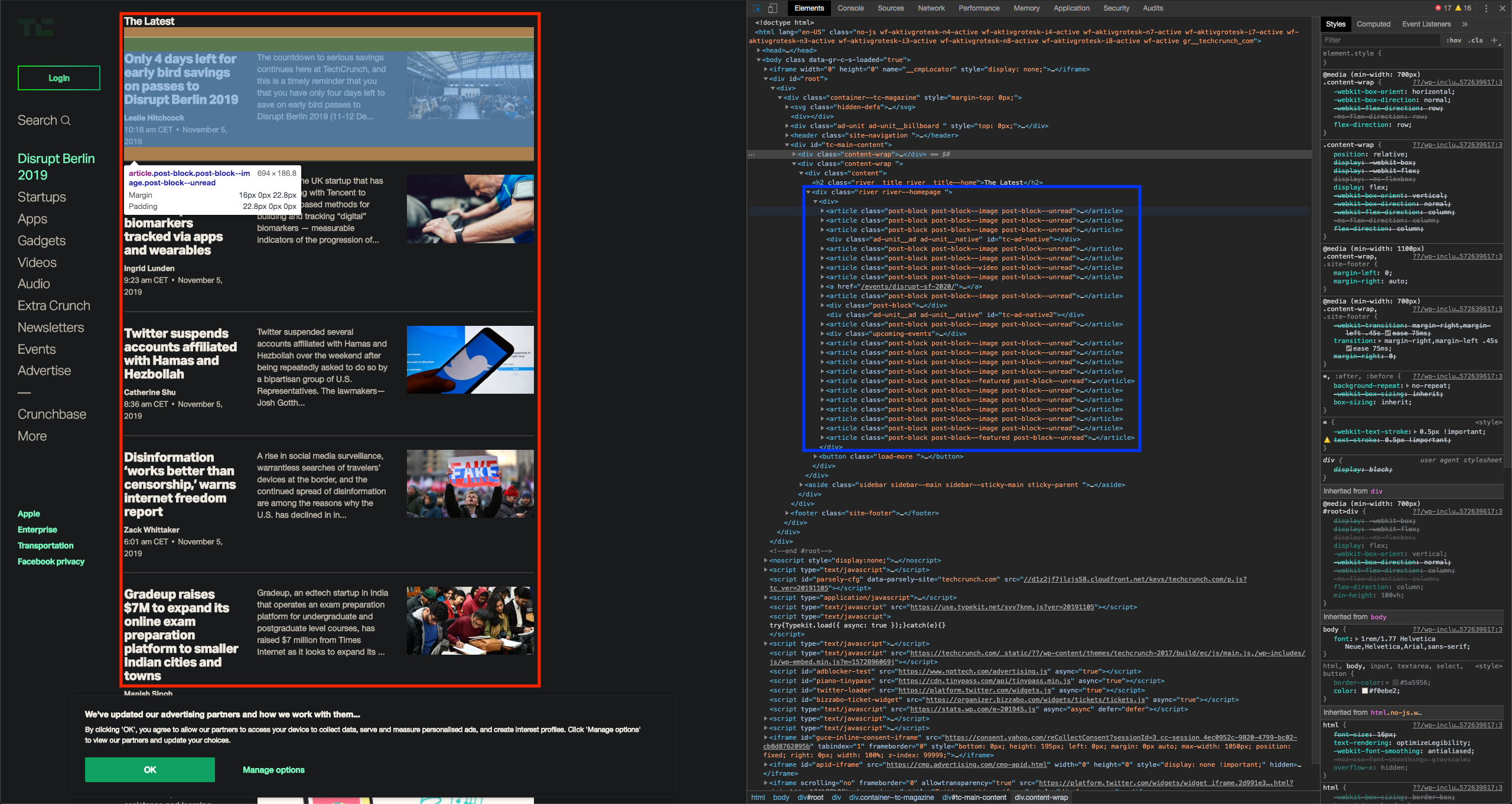
Articles are marked with elements: <article class="post-block post-block--image post-block--unread">.
When we drill down, we get to the elements with a title, content and an attribute with the URL to the article.
2. Scraping
Now that we identified the elements we would like to parse, let’s fetch the TechCrunch webpage and parse it with BeautifulSoup’s HTML parser.
url = "https://techcrunch.com/"
response = requests.get(url)
soup = bs4.BeautifulSoup(response.text, "html.parser")
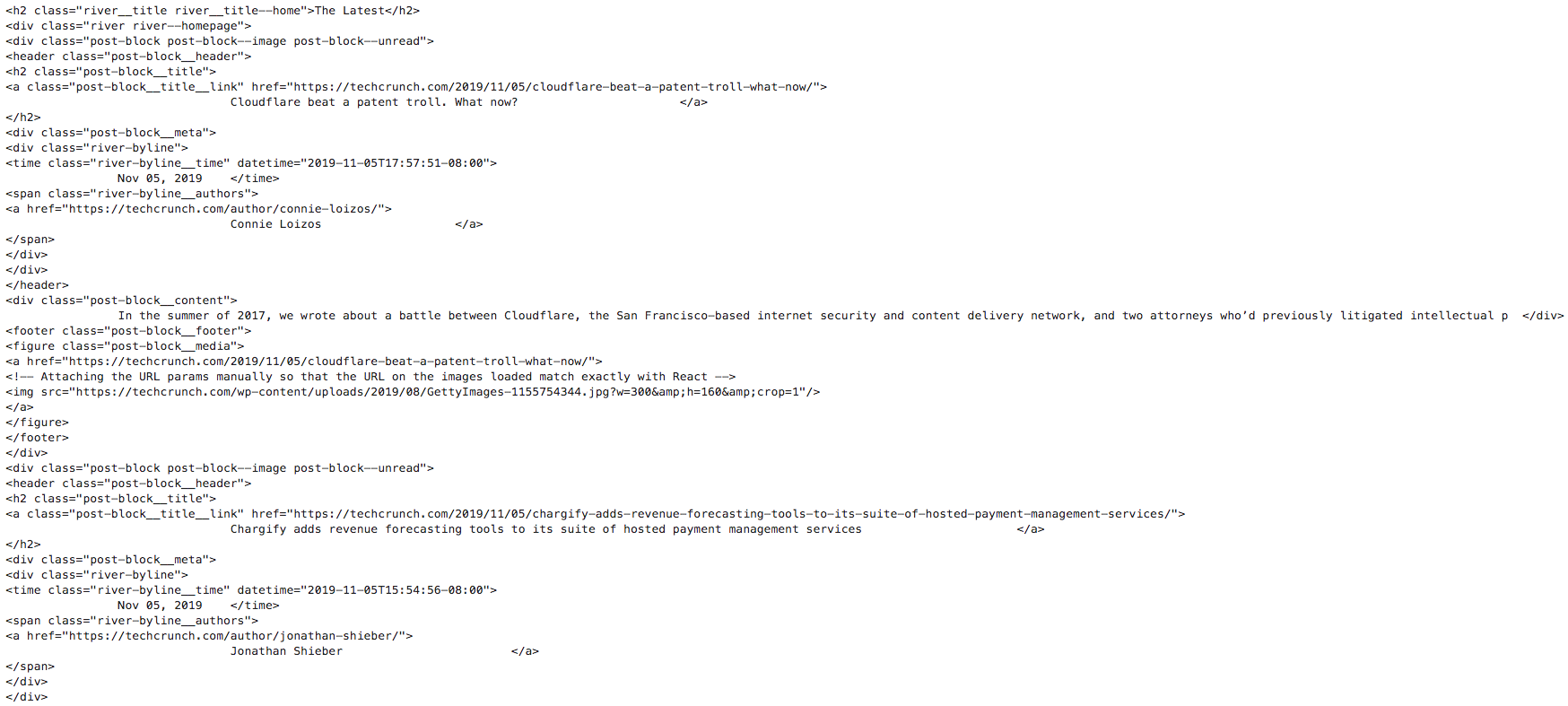
In the parsed output above, we see that instead of <article> elements, there are <div> elements - you can read more about why this happens in the answer on StackOverflow.
To parse articles from the parsed HTML, we need to define HTML elements:
- parent element of an article is marked with
divand attributesclass="post-block post-block--image post-block--unread" - title and url are in a separate block from the content:
class="post-block__title__link",class="post-block__content"respectevly.
The code below parses article’s title, short content and a URL and it appends them to lists.
article_titles, article_contents, article_hrefs = [], [], []
for tag in soup.findAll("div", {"class": "post-block post-block--image post-block--unread"}):
tag_header = tag.find("a", {"class": "post-block__title__link"})
tag_content = tag.find("div", {"class": "post-block__content"})
article_title = tag_header.get_text().strip()
article_href = tag_header["href"]
article_content = tag_content.get_text().strip()
article_titles.append(article_title)
article_contents.append(article_content)
article_hrefs.append(article_href)
3. Creating an Excel report
We have parsed the content of the webpage. Now let’s save it to an Excel file. Pandas DataFrame enables us to create an Excel report with few commands. Let’s create a pandas DataFrame from the lists.
df = pd.DataFrame({"title": article_titles, "content": article_contents, "href": article_hrefs})
df.shape
(20, 3)
df.head()
| title | content | href | |
|---|---|---|---|
| 0 | San Francisco smokes Juul’s hopes by voting to... | Voters in San Francisco have resoundingly reje... | https://techcrunch.com/2019/11/06/san-francisc... |
| 1 | Neo4j introduces new cloud service to simplify... | Neo4j, a popular graph database, is available ... | https://techcrunch.com/2019/11/06/neo4j-introd... |
| 2 | China’s Didi to relaunch Hitch carpooling serv... | Chinese ride-hailing firm Didi Chuxing said to... | https://techcrunch.com/2019/11/06/didi-hitch-c... |
| 3 | GoCardless partners with TransferWise to bring... | GoCardless, the London fintech that makes it e... | https://techcrunch.com/2019/11/06/gocardless-t... |
| 4 | 72 hours left for early bird passes to Disrupt... | Did you know that the cuckoo clock originated ... | https://techcrunch.com/2019/11/06/72-hours-lef... |
def auto_adjust_excel_columns(worksheet, df):
for idx, col in enumerate(df): # loop through all columns
series = df[col]
max_len = (
max(
(
series.astype(str).map(len).max(), # len of largest item
len(str(series.name)), # len of column name/header
)
)
+ 1
) # adding a little extra space
worksheet.set_column(idx, idx, max_len) # set column width
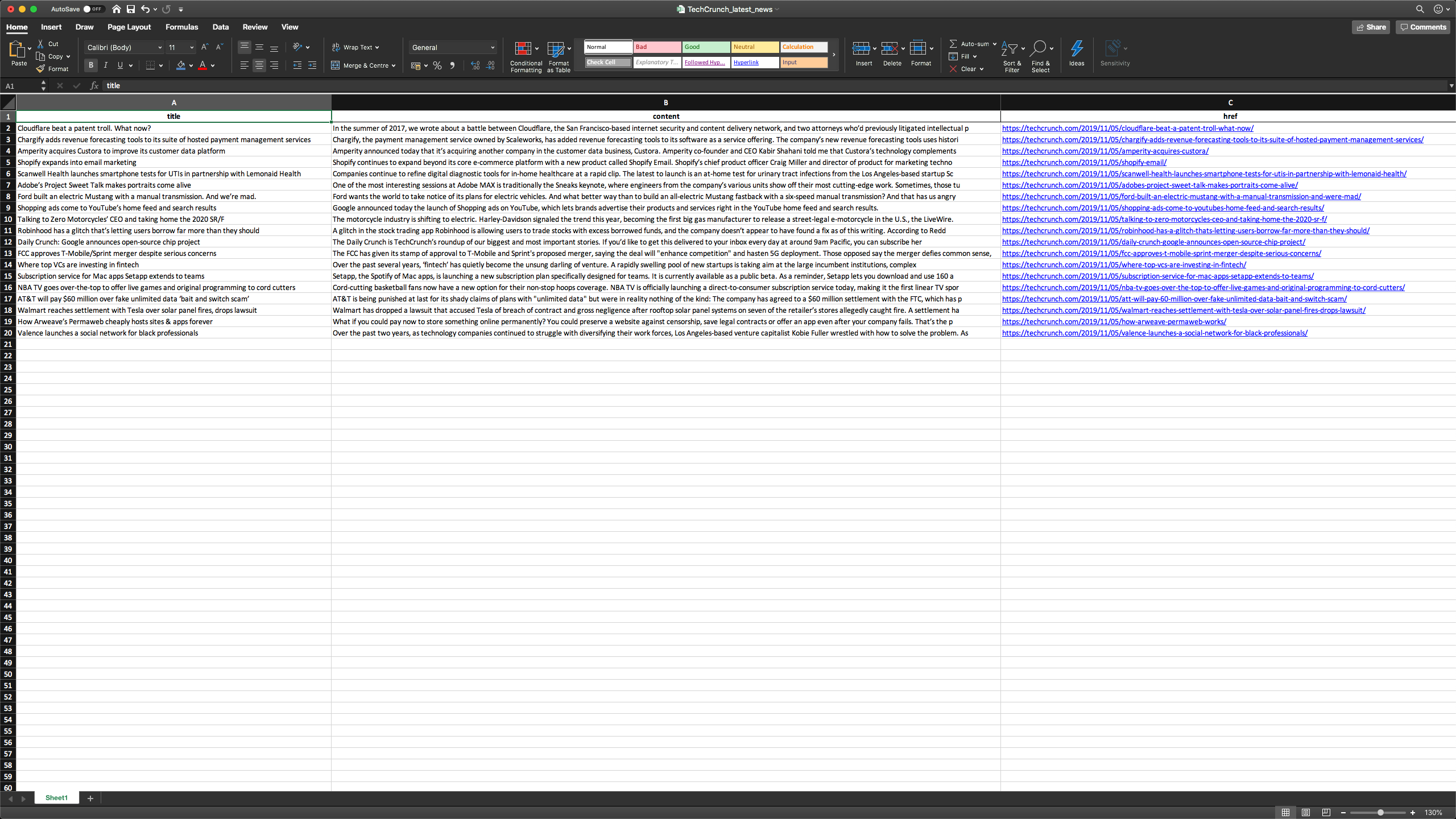
By default, Excel columns are not auto-adjusted, so we need to set the width of the columns (a maximum between column title and largest item in the column). The code below auto-adjusts columns and it creates an Excel file from the DataFrame.
writer = pd.ExcelWriter('TechCrunch_latest_news.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1', index=False)
auto_adjust_excel_columns(writer.sheets['Sheet1'], df)
writer.save()
Conclusion
In this blogpost, we scraped the latest articles from TechCrunch and save them in a format that can be used by non-developers. Python and its libraries enable us to achieve that with a few commands. Each website s different and it requires a bit of manual searching for the right elements to parse.
Did you find this tutorial useful? Have any suggestions? Let me know in the comments below.