LSTM for time series prediction

The idea of using a Neural Network (NN) to predict the stock price movement on the market is as old as NNs. Intuitively, it seems difficult to predict the future price movement looking only at its past. There are many tutorials on how to predict the price trend or its power, which simplifies the problem. I’ve decided to try to predict Volume Weighted Average Price with LSTM because it seems challenging and fun.
In this blog post, I am going to train a Long Short Term Memory Neural Network (LSTM) with PyTorch on Bitcoin trading data and use the it to predict the price of unseen trading data. I had quite some difficulties with finding intermediate tutorials with a repeatable example of training an LSTM for time series prediction, so I’ve put together this Jupyter notebook to help you to get started.
Here are a few links you might be interested in:
- Intro to Machine Learning
- Intro to Programming
- Data Science for Business Leaders
- AI for Healthcare
- Autonomous Systems
- Learn SQL
Disclosure: Bear in mind that some of the links above are affiliate links and if you go through them to make a purchase I will earn a commission. Keep in mind that I link courses because of their quality and not because of the commission I receive from your purchases. The decision is yours, and whether or not you decide to buy something is completely up to you.
Loading Necessary Dependencies
Let’s import the libraries that we are going to use for data manipulation, visualization, training the model, etc. We are going to train the LSTM using PyTorch library.
%matplotlib inline
import glob
from platform import python_version
import matplotlib
import numpy as np
import pandas as pd
import sklearn
import torch
print("python version==%s" % python_version())
print("pandas==%s" % pd.__version__)
print("numpy==%s" % np.__version__)
print("sklearn==%s" % sklearn.__version__)
print("torch==%s" % torch.__version__)
print("matplotlib==%s" % matplotlib.__version__)
python version==3.7.3
pandas==0.25.0
numpy==1.16.3
sklearn==0.21.0
torch==1.1.0
matplotlib==3.0.3
import matplotlib.pyplot as plt
plt.rcParams[
"figure.facecolor"
] = "w" # force white background on plots when using dark mode in JupyterLab
Loading the Data
We are going to analyze XBTUSD trading data from BitMex. The daily files are publicly available to download. I didn’t bother to write the code to download the data automatically, I’ve simply clicked a couple of times to download the files.
Let’s lists all the files, read them to a pandas DataFrame and filter the trading data by XBTUSD symbol. It is important to sort the DataFrame by timestamp as there are multiple daily files so that they don’t get mixed up.
files = sorted(glob.glob('data/*.csv.gz'))
files
['data/20190801.csv.gz',
'data/20190802.csv.gz',
'data/20190803.csv.gz',
'data/20190804.csv.gz',
'data/20190805.csv.gz',
'data/20190806.csv.gz',
'data/20190807.csv.gz',
'data/20190808.csv.gz',
'data/20190809.csv.gz',
'data/20190810.csv.gz',
'data/20190811.csv.gz',
'data/20190812.csv.gz',
'data/20190813.csv.gz',
'data/20190814.csv.gz',
'data/20190815.csv.gz',
'data/20190816.csv.gz',
'data/20190817.csv.gz',
'data/20190818.csv.gz',
'data/20190819.csv.gz',
'data/20190820.csv.gz',
'data/20190821.csv.gz',
'data/20190822.csv.gz',
'data/20190823.csv.gz',
'data/20190824.csv.gz',
'data/20190825.csv.gz',
'data/20190826.csv.gz',
'data/20190827.csv.gz',
'data/20190828.csv.gz',
'data/20190829.csv.gz',
'data/20190830.csv.gz',
'data/20190831.csv.gz',
'data/20190901.csv.gz',
'data/20190902.csv.gz',
'data/20190903.csv.gz',
'data/20190904.csv.gz',
'data/20190905.csv.gz',
'data/20190906.csv.gz',
'data/20190907.csv.gz',
'data/20190908.csv.gz',
'data/20190909.csv.gz',
'data/20190910.csv.gz',
'data/20190911.csv.gz',
'data/20190912.csv.gz',
'data/20190913.csv.gz',
'data/20190914.csv.gz',
'data/20190915.csv.gz',
'data/20190916.csv.gz',
'data/20190917.csv.gz']
df = pd.concat(map(pd.read_csv, files))
df.shape
(44957218, 10)
df = df[df.symbol == 'XBTUSD']
df.shape
(36708098, 10)
df.timestamp = pd.to_datetime(df.timestamp.str.replace('D', 'T'))
df = df.sort_values('timestamp')
df.set_index('timestamp', inplace=True)
df.head()
| symbol | side | size | price | tickDirection | trdMatchID | grossValue | homeNotional | foreignNotional | |
|---|---|---|---|---|---|---|---|---|---|
| timestamp | |||||||||
| 2019-08-01 00:00:03.817388 | XBTUSD | Sell | 849 | 10088.5 | ZeroMinusTick | 7b395739-b7d1-83ad-f9a2-13fb693dab0c | 8415288 | 0.084153 | 849.0 |
| 2019-08-01 00:00:03.817388 | XBTUSD | Sell | 1651 | 10088.5 | ZeroMinusTick | 9313c5ef-ce60-f22e-c099-83e896a63628 | 16364712 | 0.163647 | 1651.0 |
| 2019-08-01 00:00:03.950526 | XBTUSD | Buy | 34679 | 10089.0 | PlusTick | 756bfe44-b298-9085-2381-fbeee0164a80 | 343738248 | 3.437382 | 34679.0 |
| 2019-08-01 00:00:03.950526 | XBTUSD | Buy | 35 | 10089.0 | ZeroPlusTick | 788929c5-c8cb-2f36-4184-7f184852a89a | 346920 | 0.003469 | 35.0 |
| 2019-08-01 00:00:03.950526 | XBTUSD | Buy | 35 | 10089.0 | ZeroPlusTick | d38ab9fc-892a-1e0f-f1e6-dea1fe1c954c | 346920 | 0.003469 | 35.0 |
Each row represents a trade:
- timestamp in microsecond accuracy,
- symbol of the contract traded,
- side of the trade, buy or sell,
- size represents the number of contracts (the number of USD traded),
- price of the contract,
- tickDirection describes an increase/decrease in the price since the previous transaction,
- trdMatchID is the unique trade ID,
- grossValue is the number of satoshis exchanged,
- homeNotional is the amount of XBT in the trade,
- foreignNotional is the amount of USD in the trade.
We are going to use 3 columns: timestamp, price and foreignNotional.
Data Preprocessing
Let’s calculate Volume Weighted Average Price (VWAP) in 1 minute time intervals. The data representation where we group trades by the predefined time interval is called time bars. Is this the best way to represent the trade data for modeling? According to Lopez de Prado, trades on the market are not uniformly distributed over time. There are periods with high activity, eg. right before future contracts expire, and grouping of data in predefined time intervals would oversample the data in some time bars and undersample it at others. Financial Machine Learning Part 0: Bars is a nice summary of the 2nd Chapter of Lopez de Prado’s book Advances in Financial Machine Learning Book. Time bars may not be the best data representation, but we are going to use them regardless.
df_vwap = df.groupby(pd.Grouper(freq="1Min")).apply(
lambda row: pd.np.sum(row.price * row.foreignNotional) / pd.np.sum(row.foreignNotional)
)
df_vwap.shape
(69120,)
ax = df_vwap.plot(figsize=(14, 7))
ax.axvline("2019-09-01", linestyle="--", c="black")
ax.axvline("2019-09-05", linestyle="--", c="black")
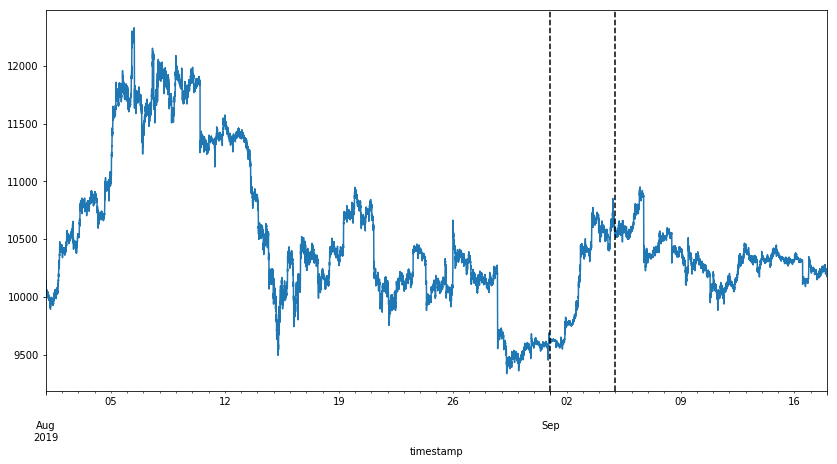
The plot shows time bars with VWAP from 1st of August till the 17th of September 2019. We are going to use the first part of the data for the training set, part in-between for validation set and the last part of the data for the test set (vertical lines are delimiters). We can observe volatility in the VWAP, where the price reaches its highs in the first part of August and lows at the end of August. The high and low are captured in the training set, which is important, as the model most probably wouldn’t work well on unseen VWAP intervals.
df_train = df_vwap[df_vwap.index < "2019-09-01"].to_frame(name="vwap")
df_train.shape
(44640, 1)
df_val = df_vwap[(df_vwap.index >= "2019-09-01") & (df_vwap.index < "2019-09-05")].to_frame(name="vwap")
df_val.shape
(5760, 1)
df_test = df_vwap[df_vwap.index >= "2019-09-05"].to_frame(name='vwap')
df_test.shape
(18720, 1)
Scaling the Data
To help the LSTM model to converge faster it is important to scale the data. It is possible that large values in the inputs slows down the learning. We are going to use StandardScaler from sklearn library to scale the data. The scaler is fit on the training set and it is used to transform the unseen trade data on validation and test set. If we would fit the scalar on all data, the model would overfit and it would achieve good results on this data, but performance would suffer on the real world data.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_arr = scaler.fit_transform(df_train)
val_arr = scaler.transform(df_val)
test_arr = scaler.transform(df_test)
Transforming the Data
After scaling we need to transform the data into a format that is appropriate for modeling with LSTM. We transform the long sequence of data into many shorter sequences (100 time bars per sequence) that are shifted by a single time bar.
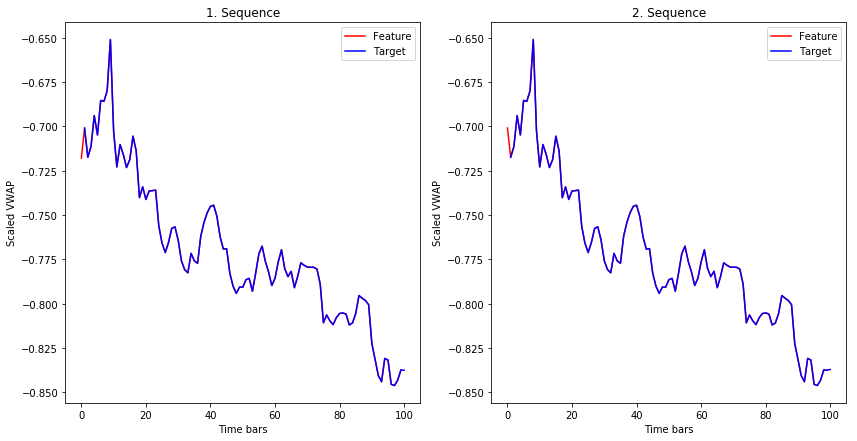
The plot below shows the first and the second sequence in the training set. The length of both sequences is 100 time bars. We can observe that the target of both sequences is almost the same as the feature, the differences are in the first and in the last time bar.
How does the LSTM use the sequence in the training phase? Let’s focus on the 1st sequence. The model takes the feature of the time bar at index 0 and it tries to predict the target of the time bar at index 1. Then it takes the feature of the time bar at index 1 and it tries to predict the target of the time bar at index 2, etc. The feature of 2nd sequence is shifted by 1 time bar from the feature of 1st sequence, the feature of 3rd sequence is shifted by 1 time bar from 2nd sequence, etc. With this procedure, we get many shorter sequences that are shifted by a single time bar.
Note that in classification or regression tasks, we usually have a set of features and a target that we are trying to predict. In this example with LSTM, the feature and the target are from the same sequence, the only difference is that the target is shifted by 1 time bar.
def transform_data(arr, seq_len):
x, y = [], []
for i in range(len(arr) - seq_len):
x_i = arr[i : i + seq_len]
y_i = arr[i + 1 : i + seq_len + 1]
x.append(x_i)
y.append(y_i)
x_arr = np.array(x).reshape(-1, seq_len)
y_arr = np.array(y).reshape(-1, seq_len)
x_var = Variable(torch.from_numpy(x_arr).float())
y_var = Variable(torch.from_numpy(y_arr).float())
return x_var, y_var
from torch.autograd import Variable
seq_len = 100
x_train, y_train = transform_data(train_arr, seq_len)
x_val, y_val = transform_data(val_arr, seq_len)
x_test, y_test = transform_data(test_arr, seq_len)
def plot_sequence(axes, i, x_train, y_train):
axes[i].set_title("%d. Sequence" % (i + 1))
axes[i].set_xlabel("Time Bars")
axes[i].set_ylabel("Scaled VWAP")
axes[i].plot(range(seq_len), x_train[i].cpu().numpy(), color="r", label="Feature")
axes[i].plot(range(1, seq_len + 1), y_train[i].cpu().numpy(), color="b", label="Target")
axes[i].legend()
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 7))
plot_sequence(axes, 0, x_train, y_train)
plot_sequence(axes, 1, x_train, y_train)
Long Short Term Memory Neural Network
The Long Short Term Memory neural network is a type of a Recurrent Neural Network (RNN). RNNs use previous time events to inform the later ones. For example, to classify what kind of event is happening in a movie, the model needs to use information about previous events. RNNs work well if the problem requires only recent information to perform the present task. If the problem requires long term dependencies, RNN would struggle to model it. The LSTM was designed to learn long term dependencies. It remembers the information for long periods. LSTM was introduced by S Hochreiter, J Schmidhuber in 1997. To learn more about LSTMs read a great colah blog post which offers a good explanation.
The code below is an implementation of a stateful LSTM for time series prediction. It has an LSTMCell unit and a linear layer to model a sequence of a time series. The model can generate the future values of a time series and it can be trained using teacher forcing (a concept that I am going to describe later).
import torch.nn as nn
import torch.optim as optim
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lstm = nn.LSTMCell(self.input_size, self.hidden_size)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, future=0, y=None):
outputs = []
# reset the state of LSTM
# the state is kept till the end of the sequence
h_t = torch.zeros(input.size(0), self.hidden_size, dtype=torch.float32)
c_t = torch.zeros(input.size(0), self.hidden_size, dtype=torch.float32)
for i, input_t in enumerate(input.chunk(input.size(1), dim=1)):
h_t, c_t = self.lstm(input_t, (h_t, c_t))
output = self.linear(h_t)
outputs += [output]
for i in range(future):
if y is not None and random.random() > 0.5:
output = y[:, [i]] # teacher forcing
h_t, c_t = self.lstm(output, (h_t, c_t))
output = self.linear(h_t)
outputs += [output]
outputs = torch.stack(outputs, 1).squeeze(2)
return outputs
import time
import random
class Optimization:
""" A helper class to train, test and diagnose the LSTM"""
def __init__(self, model, loss_fn, optimizer, scheduler):
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
self.scheduler = scheduler
self.train_losses = []
self.val_losses = []
self.futures = []
@staticmethod
def generate_batch_data(x, y, batch_size):
for batch, i in enumerate(range(0, len(x) - batch_size, batch_size)):
x_batch = x[i : i + batch_size]
y_batch = y[i : i + batch_size]
yield x_batch, y_batch, batch
def train(
self,
x_train,
y_train,
x_val=None,
y_val=None,
batch_size=100,
n_epochs=15,
do_teacher_forcing=None,
):
seq_len = x_train.shape[1]
for epoch in range(n_epochs):
start_time = time.time()
self.futures = []
train_loss = 0
for x_batch, y_batch, batch in self.generate_batch_data(x_train, y_train, batch_size):
y_pred = self._predict(x_batch, y_batch, seq_len, do_teacher_forcing)
self.optimizer.zero_grad()
loss = self.loss_fn(y_pred, y_batch)
loss.backward()
self.optimizer.step()
train_loss += loss.item()
self.scheduler.step()
train_loss /= batch
self.train_losses.append(train_loss)
self._validation(x_val, y_val, batch_size)
elapsed = time.time() - start_time
print(
"Epoch %d Train loss: %.2f. Validation loss: %.2f. Avg future: %.2f. Elapsed time: %.2fs."
% (epoch + 1, train_loss, self.val_losses[-1], np.average(self.futures), elapsed)
)
def _predict(self, x_batch, y_batch, seq_len, do_teacher_forcing):
if do_teacher_forcing:
future = random.randint(1, int(seq_len) / 2)
limit = x_batch.size(1) - future
y_pred = self.model(x_batch[:, :limit], future=future, y=y_batch[:, limit:])
else:
future = 0
y_pred = self.model(x_batch)
self.futures.append(future)
return y_pred
def _validation(self, x_val, y_val, batch_size):
if x_val is None or y_val is None:
return
with torch.no_grad():
val_loss = 0
for x_batch, y_batch, batch in self.generate_batch_data(x_val, y_val, batch_size):
y_pred = self.model(x_batch)
loss = self.loss_fn(y_pred, y_batch)
val_loss += loss.item()
val_loss /= batch
self.val_losses.append(val_loss)
def evaluate(self, x_test, y_test, batch_size, future=1):
with torch.no_grad():
test_loss = 0
actual, predicted = [], []
for x_batch, y_batch, batch in self.generate_batch_data(x_test, y_test, batch_size):
y_pred = self.model(x_batch, future=future)
y_pred = (
y_pred[:, -len(y_batch) :] if y_pred.shape[1] > y_batch.shape[1] else y_pred
)
loss = self.loss_fn(y_pred, y_batch)
test_loss += loss.item()
actual += torch.squeeze(y_batch[:, -1]).data.cpu().numpy().tolist()
predicted += torch.squeeze(y_pred[:, -1]).data.cpu().numpy().tolist()
test_loss /= batch
return actual, predicted, test_loss
def plot_losses(self):
plt.plot(self.train_losses, label="Training loss")
plt.plot(self.val_losses, label="Validation loss")
plt.legend()
plt.title("Losses")
def generate_sequence(scaler, model, x_sample, future=1000):
""" Generate future values for x_sample with the model """
y_pred_tensor = model(x_sample, future=future)
y_pred = y_pred_tensor.cpu().tolist()
y_pred = scaler.inverse_transform(y_pred)
return y_pred
def to_dataframe(actual, predicted):
return pd.DataFrame({"actual": actual, "predicted": predicted})
def inverse_transform(scalar, df, columns):
for col in columns:
df[col] = scaler.inverse_transform(df[col])
return df
Training the LSTM
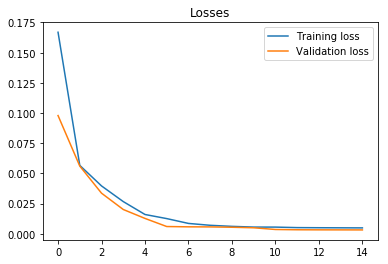
We train LSTM with 21 hidden units. A lower number of units is used so that it is less likely that LSTM would perfectly memorize the sequence. We use Mean Square Error loss function and Adam optimizer. Learning rate is set to 0.001 and it decays every 5 epochs. We train the model with 100 sequences per batch for 15 epochs. From the plot below, we can observe that training and validation loss converge after sixth epoch.
model_1 = Model(input_size=1, hidden_size=21, output_size=1)
loss_fn_1 = nn.MSELoss()
optimizer_1 = optim.Adam(model_1.parameters(), lr=1e-3)
scheduler_1 = optim.lr_scheduler.StepLR(optimizer_1, step_size=5, gamma=0.1)
optimization_1 = Optimization(model_1, loss_fn_1, optimizer_1, scheduler_1)
optimization_1.train(x_train, y_train, x_val, y_val, do_teacher_forcing=False)
Epoch 1 Train loss: 0.17. Validation loss: 0.10. Avg future: 0.00. Elapsed time: 47.97s.
Epoch 2 Train loss: 0.06. Validation loss: 0.06. Avg future: 0.00. Elapsed time: 49.29s.
Epoch 3 Train loss: 0.04. Validation loss: 0.03. Avg future: 0.00. Elapsed time: 49.40s.
Epoch 4 Train loss: 0.03. Validation loss: 0.02. Avg future: 0.00. Elapsed time: 49.28s.
Epoch 5 Train loss: 0.02. Validation loss: 0.01. Avg future: 0.00. Elapsed time: 49.55s.
Epoch 6 Train loss: 0.01. Validation loss: 0.01. Avg future: 0.00. Elapsed time: 49.41s.
Epoch 7 Train loss: 0.01. Validation loss: 0.01. Avg future: 0.00. Elapsed time: 49.15s.
Epoch 8 Train loss: 0.01. Validation loss: 0.01. Avg future: 0.00. Elapsed time: 49.32s.
Epoch 9 Train loss: 0.01. Validation loss: 0.01. Avg future: 0.00. Elapsed time: 49.37s.
Epoch 10 Train loss: 0.01. Validation loss: 0.00. Avg future: 0.00. Elapsed time: 49.43s.
Epoch 11 Train loss: 0.01. Validation loss: 0.00. Avg future: 0.00. Elapsed time: 49.41s.
Epoch 12 Train loss: 0.01. Validation loss: 0.00. Avg future: 0.00. Elapsed time: 49.52s.
Epoch 13 Train loss: 0.01. Validation loss: 0.00. Avg future: 0.00. Elapsed time: 49.31s.
Epoch 14 Train loss: 0.00. Validation loss: 0.00. Avg future: 0.00. Elapsed time: 49.26s.
Epoch 15 Train loss: 0.00. Validation loss: 0.00. Avg future: 0.00. Elapsed time: 49.29s.
optimization_1.plot_losses()
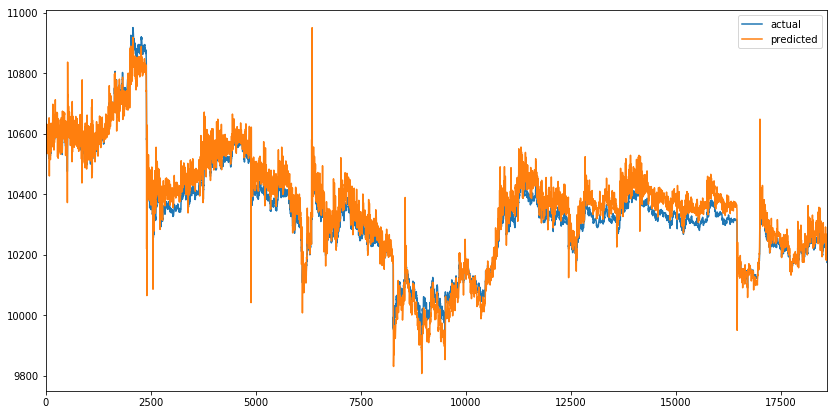
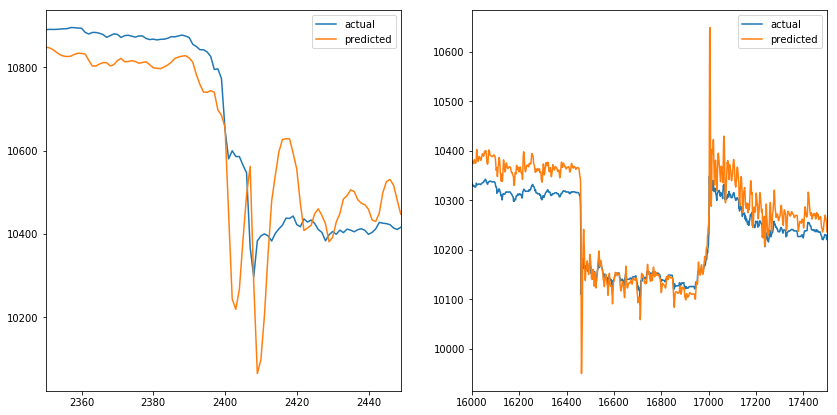
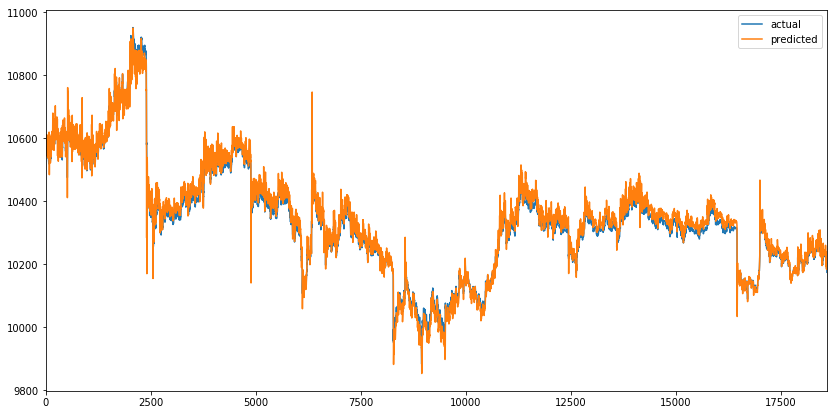
Let’s evaluate the model on the test set. The future parameter is set to 5, which means that the model outputs the VWAP where it believes it will be in the next 5 time bars (5 minutes in our example). This should make the price change visible few time bars before it occurs.
On the plot below, we can observe that predicted values closely match actual values of VWAP, which seems great on the first sight. But the future parameter was set to 5, which means that the orange line should react before a spike occurs instead of covering it.
actual_1, predicted_1, test_loss_1 = optimization_1.evaluate(x_test, y_test, future=5, batch_size=100)
df_result_1 = to_dataframe(actual_1, predicted_1)
df_result_1 = inverse_transform(scaler, df_result_1, ['actual', 'predicted'])
df_result_1.plot(figsize=(14, 7))
print("Test loss %.4f" % test_loss_1)
Test loss 0.0009
When we zoom into the spikes (one on the start and the other on the end of the time series). We can observe that predicted values mimic the actual values. When the actual value changes direction, predicted value follows, which doesn’t help us much. The same happens when we increase the future parameter (like it doesn’t affect the predicted line).
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 7))
df_result_1.iloc[2350:2450].plot(ax=axes[0], figsize=(14, 7))
df_result_1.iloc[16000:17500].plot(ax=axes[1], figsize=(14, 7))
Let’s generate 1000 time bars for the first test sequence with the model and compare predicted, generated and actual VWAP. We can observe that while the model outputs predicted values, they are close to actual values. But when it starts to generate values, the output almost resembles the sine wave. After certain period values converge to 9600.
x_sample = x_test[0].reshape(1, -1)
y_sample = df_test.vwap[:1100]
y_pred1 = generate_sequence(scaler, optimization_1.model, x_sample)
plt.figure(figsize=(14, 7))
plt.plot(range(100), y_pred1[0][:100], color="blue", lw=2, label="Predicted VWAP")
plt.plot(range(100, 1100), y_pred1[0][100:], "--", color="blue", lw=2, label="Generated VWAP")
plt.plot(range(0, 1100), y_sample, color="red", label="Actual VWAP")
plt.legend()
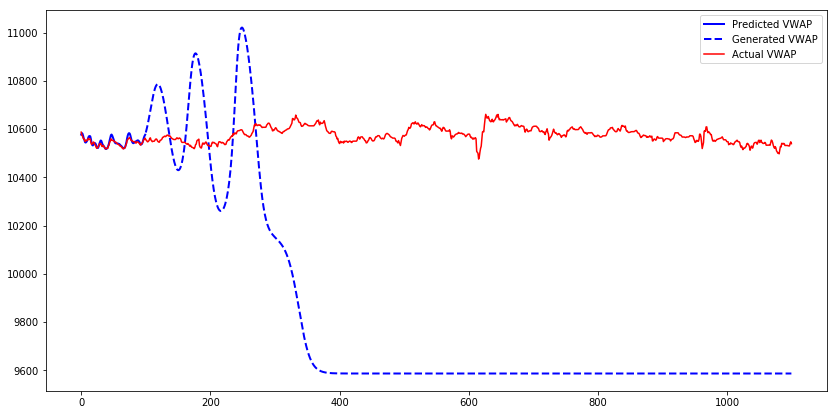
This behavior could occur because the model was trained only with true inputs and never with generated inputs. When the model gets fed the generated output on the input, it does a poor job of generating the next values. Teacher forcing is a concept that deals with this issue.
Teacher Forcing
The Teacher forcing is a method for training Recurrent Neural Networks that use the output from a previous time step as an input. When the RNN is trained, it can generate a sequence by using the previous output as current input. The same process can be used during training, but the model can become unstable or it does not converge. Teacher forcing is an approach to address those issues during training. It is commonly used in language models.
We are going to use an extension of Teacher forcing, called Scheduled sampling. The model will use its generated output as an input with a certain probability during training. At first, the probability of a model seeing its generated output is small and then it gradually increases during training. Note that in this example, we use a random probability, which doesn’t increase during the training process.
Let’s train a model with the same parameters as before but with the teacher forcing enabled. After 7 epochs, the training and validation loss converge.
model_2 = Model(input_size=1, hidden_size=21, output_size=1)
loss_fn_2 = nn.MSELoss()
optimizer_2 = optim.Adam(model_2.parameters(), lr=1e-3)
scheduler_2 = optim.lr_scheduler.StepLR(optimizer_2, step_size=5, gamma=0.1)
optimization_2 = Optimization(model_2, loss_fn_2, optimizer_2, scheduler_2)
optimization_2.train(x_train, y_train, x_val, y_val, do_teacher_forcing=True)
Epoch 1 Train loss: 0.21. Validation loss: 0.23. Avg future: 24.83. Elapsed time: 49.32s.
Epoch 2 Train loss: 0.06. Validation loss: 0.07. Avg future: 25.10. Elapsed time: 49.43s.
Epoch 3 Train loss: 0.04. Validation loss: 0.05. Avg future: 25.53. Elapsed time: 49.51s.
Epoch 4 Train loss: 0.03. Validation loss: 0.03. Avg future: 25.83. Elapsed time: 49.70s.
Epoch 5 Train loss: 0.02. Validation loss: 0.02. Avg future: 25.33. Elapsed time: 49.58s.
Epoch 6 Train loss: 0.03. Validation loss: 0.01. Avg future: 24.80. Elapsed time: 49.39s.
Epoch 7 Train loss: 0.02. Validation loss: 0.01. Avg future: 24.84. Elapsed time: 49.56s.
Epoch 8 Train loss: 0.01. Validation loss: 0.01. Avg future: 25.53. Elapsed time: 49.41s.
Epoch 9 Train loss: 0.01. Validation loss: 0.01. Avg future: 25.54. Elapsed time: 49.63s.
Epoch 10 Train loss: 0.01. Validation loss: 0.00. Avg future: 26.65. Elapsed time: 49.43s.
Epoch 11 Train loss: 0.01. Validation loss: 0.00. Avg future: 25.96. Elapsed time: 49.48s.
Epoch 12 Train loss: 0.01. Validation loss: 0.00. Avg future: 26.09. Elapsed time: 49.45s.
Epoch 13 Train loss: 0.01. Validation loss: 0.00. Avg future: 26.16. Elapsed time: 49.83s.
Epoch 14 Train loss: 0.01. Validation loss: 0.00. Avg future: 24.41. Elapsed time: 49.48s.
Epoch 15 Train loss: 0.01. Validation loss: 0.00. Avg future: 25.20. Elapsed time: 49.37s.
optimization_2.plot_losses()
actual_2, predicted_2, test_loss_2 = optimization_2.evaluate(x_test, y_test, batch_size=100, future=5)
df_result_2 = to_dataframe(actual_2, predicted_2)
df_result_2 = inverse_transform(scaler, df_result_2, ["actual", "predicted"])
df_result_2.plot(figsize=(14, 7))
print("Test loss %.4f" % test_loss_2)
Test loss 0.0006
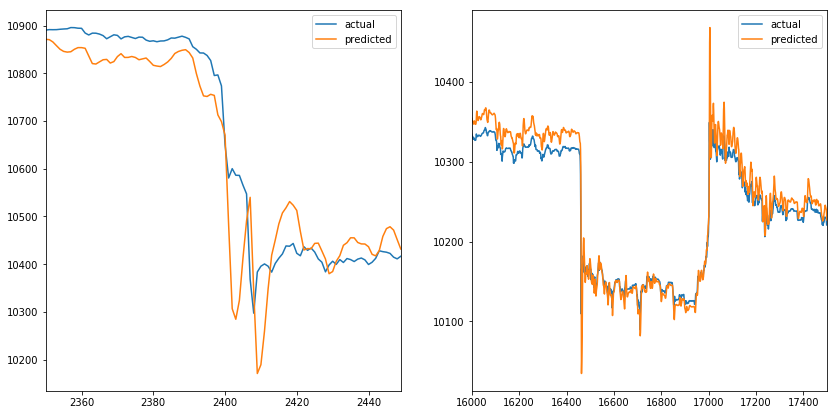
We can observe a similar predicted sequence as before. When we zoom into the spikes, similar behavior of the model can be observed, where predicted values mimic the actual values. It seems like teacher forcing didn’t solve the problem.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 7))
df_result_2.iloc[2350:2450].plot(ax=axes[0], figsize=(14, 7))
df_result_2.iloc[16000:17500].plot(ax=axes[1], figsize=(14, 7))
Let’s generate 1000 time bars for the first test sequence with the model trained with teacher forcing.
y_pred2 = generate_sequence(scaler, optimization_2.model, x_sample)
plt.figure(figsize=(14, 7))
plt.plot(range(100), y_pred2[0][:100], color="blue", lw=2, label="Predicted VWAP")
plt.plot(range(100, 1100), y_pred2[0][100:], "--", color="blue", lw=2, label="Generated VWAP")
plt.plot(range(0, 1100), y_sample, color="red", label="Actual VWAP")
plt.legend()
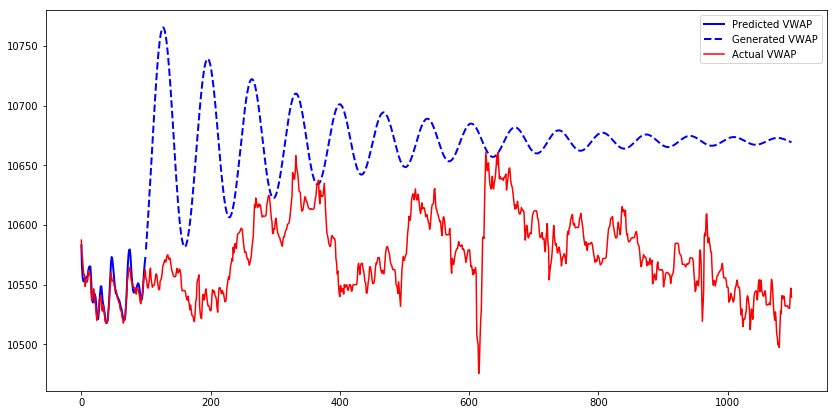
The generated sequence from the model trained with teacher forcing needs longer to converge. Another observation about the generated sequence is that when it is increasing, it will continue to increase to some point, then start to decrease and the pattern repeats until the sequence converges. The pattern looks like a sine wave with decreasing amplitude.
Conclusion
The result of this experiment is that the predictions of the model mimic actual values of the sequence. The first and second model do not detect price changes before they occur. Adding another feature (like volume) might help the model to detect the price changes before they occur, but then the model would need to generate two features to use the output of those as an input in next step, which would complicate the model. Using a more complex model (multiple LSTMCells, increase the number of hidden units) might not help as the model has the capacity to predict VWAP time series as seen in the plots above. More advanced methods of teacher forcing might help so that the model would improve sequence generation skills.